Architecting AI-Powered Image Content Product Search in 5 Hours
A senior-level system architecture design for AI image analysis, attribute extraction, and hybrid search across 100,000+ S3 images, designed in ~5 hours by a developer with 1.5 years of experience.
Last Updated: 2026-07-04 | Tags: System Design, AWS, Bedrock, OpenSearch, Vector Search, AI Architecture

Just 1.5 years into my software engineering career, I was presented with a senior-level system design interview challenge: designing an end-to-end backend architecture to analyze over 100,000 product images in AWS S3 and enable fine-grained, natural-language visual search.
I had only around ~5 hours of time on my end to analyze the problem, formulate the technical architecture, design asynchronous processing pipelines, define database schemas, map search execution flows, and evaluate core trade-offs.
This article captures the complete problem statement and the exact system architecture document I produced during that ~5-hour effort.
The Interview Problem Statement
We have approximately 100,000 product images stored in AWS S3. We need to design a backend solution that can:
- Analyze each product image using an AI image analysis service.
- Extract and store searchable metadata in a datastore.
- Enable users and administrators to search for products based on the image content.
For example, a user should be able to perform a search such as:
- "Show all dresses with red flowers"
- "Green t shirt with no prints"
The Architecture Solution
1. Overview
Objective: Design a scalable, fault-tolerant backend that analyses ~100,000 product images already stored in S3, extracts AI-generated metadata, persists it, and serves natural-language product search by image content (e.g., "dresses with red flowers", "green t-shirt with no prints").
The solution must:
- Process product images stored in S3 using an AI image analysis service.
- Extract structured attributes and a semantic embedding per image.
- Store metadata in a durable source of truth and a search index.
- Support natural-language search, including exact filters and negation.
- Remain scalable, asynchronous, and fault tolerant.
Key Insight: The query "green t-shirt with no prints" contains a negation (no prints) plus exact constraints (green, t-shirt). Pure vector search fails here—an embedding of that text sits close to t-shirts that do have prints. The design therefore pairs precise structured attributes (for filtering and negation) with embeddings (for fuzzy intent like "red flowers"). That hybrid model is the spine of the solution.
2. Assumptions
- Approximately 100,000 product images are already present in AWS S3.
- A product can have multiple images; images are the individual unit of analysis.
- AI analysis runs asynchronously, completely decoupled from any upload path.
- Aurora PostgreSQL is the source of truth. OpenSearch is the search index, rebuildable from Aurora at any time.
- A controlled vocabulary (categories, colours, patterns) is shared by the extraction and query parsing prompts.
- Amazon Bedrock provides both the attribute model (VLM) and the embedding model (Titan Multimodal).
3. High Level Architecture
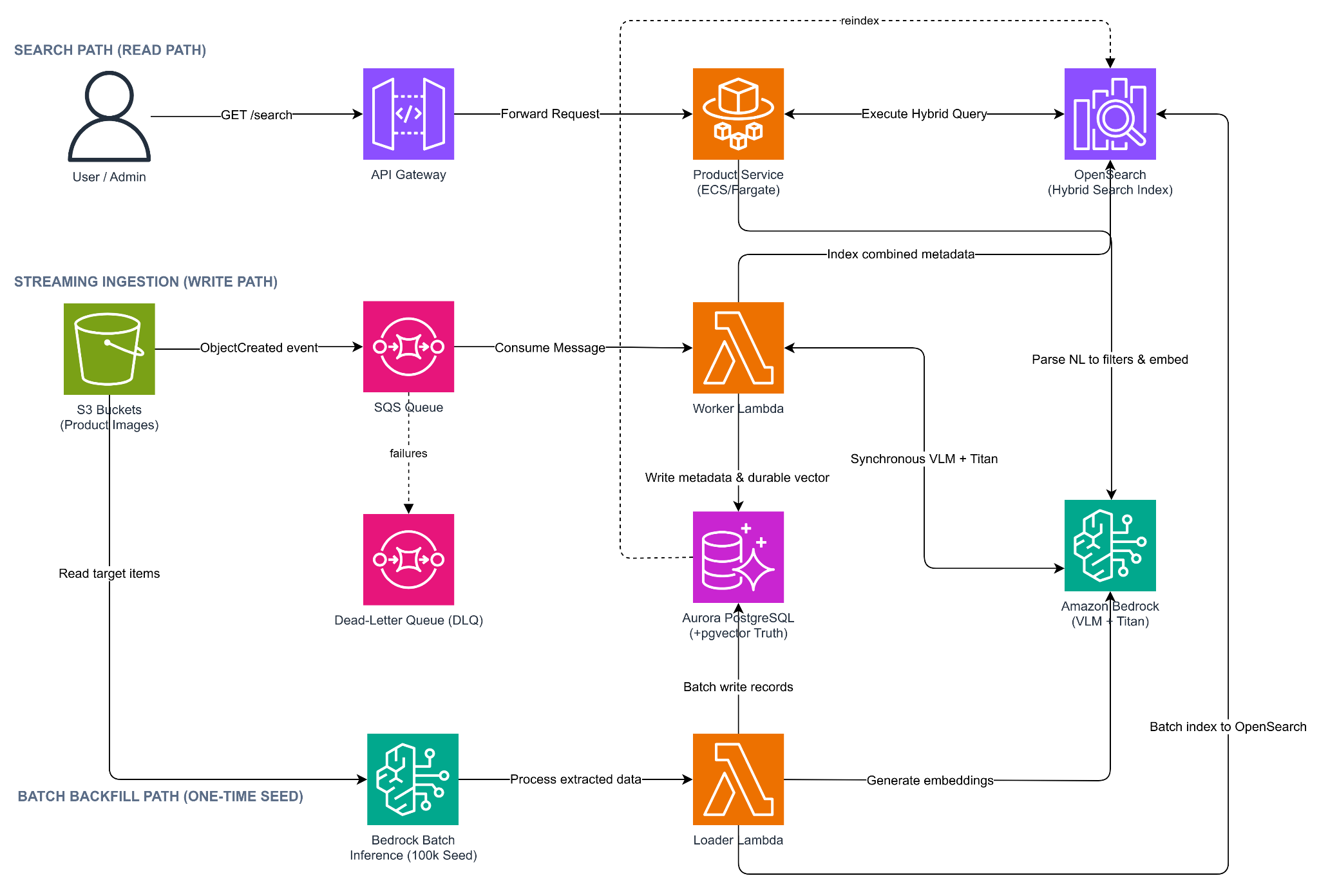
Components:
- S3: Stores the raw product images; emits an event when a new image arrives.
- SQS (+ DLQ): Buffers and decouples analysis jobs, caps concurrency against model quotas, and isolates failures.
- Worker Lambda: Consumes the queue and runs AI analysis for each image (idempotent on
s3_key+content_hash), invokes Bedrock, stores metadata in Aurora, and indexes OpenSearch. - Bedrock: Runs the VLM that extracts structured attributes and the Titan model that produces the image embedding; called synchronously and returns both to the caller.
- Bedrock Batch Inference + Loader Lambda: One-time backfill path: Batch Inference extracts attributes for the 100k seed asynchronously (~50% cheaper, within quota); the Loader Lambda then generates embeddings and writes to Aurora and OpenSearch.
- Aurora PostgreSQL + pgvector: Relational source of truth for products, images, and analysis; also holds the durable vector copy.
- OpenSearch: Search index combining exact filters, BM25 full-text, and kNN vector ranking.
- API Gateway + Product Service: API Gateway is the public entry point; a Node.js microservice (ECS/Fargate) runs query understanding (Bedrock) and executes the hybrid search against OpenSearch (chosen over a Lambda for persistent connection pooling and microservice stack fit).
4. Image Processing Flow
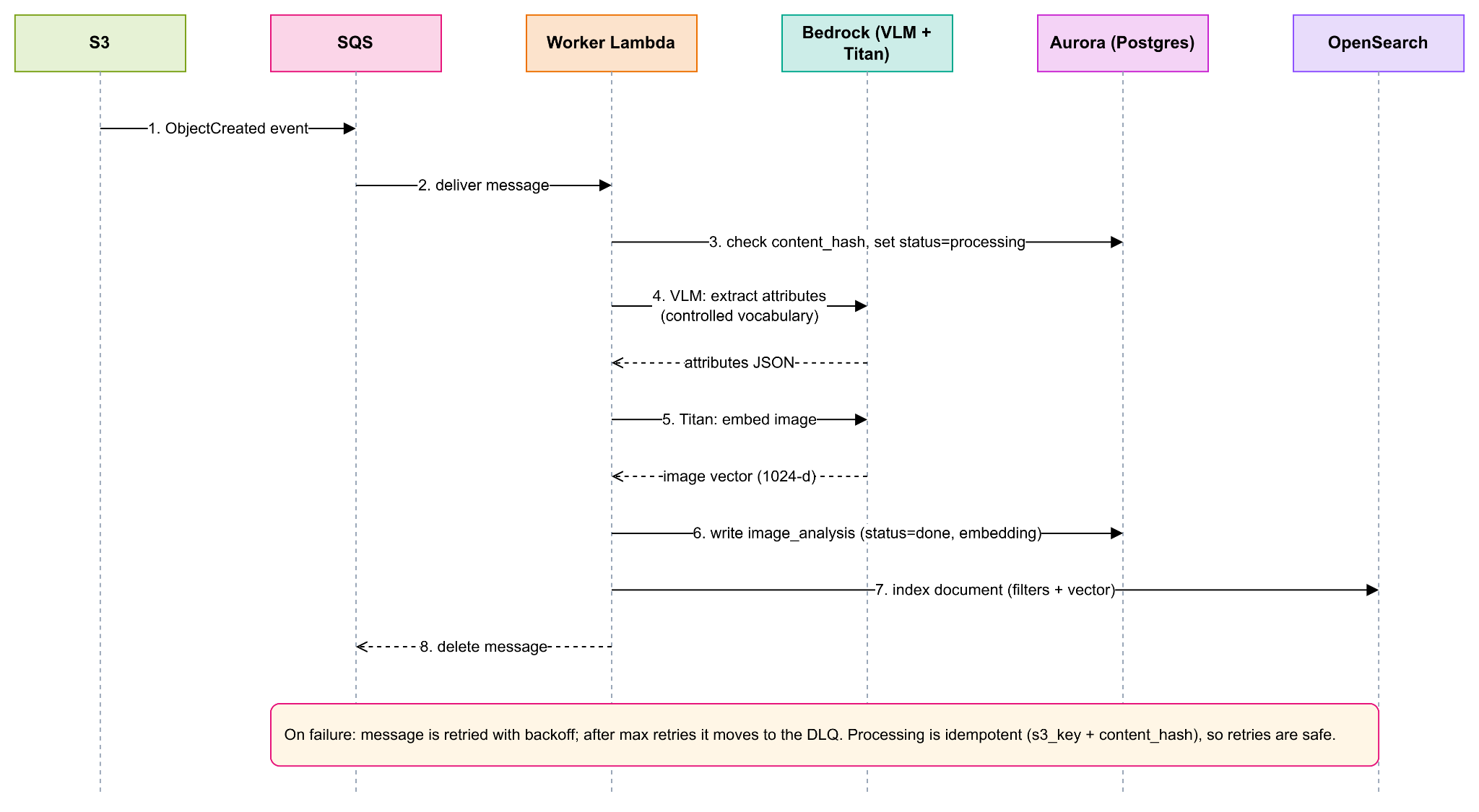
Why Asynchronous:
AI analysis is slow (hundreds of milliseconds to seconds per image) and rate-limited by model quotas, so it must not block any request path. A queue-based pipeline lets the system absorb the one-time 100k backfill and ongoing additions at a controlled rate, retry transient model/throttling errors with backoff, and route permanent failures to a dead-letter queue without losing work. Because processing is idempotent (keyed on s3_key + content_hash) and tracks per-image status, retries are safe and coverage is always known.
Backfill Note: The same SQS + Worker path seeds the catalogue. As a cost optimization, the one-time 100k extraction can run through Bedrock Batch Inference (asynchronous, ~50% cheaper), with a loader then writing results and embeddings.
5. Search Flow
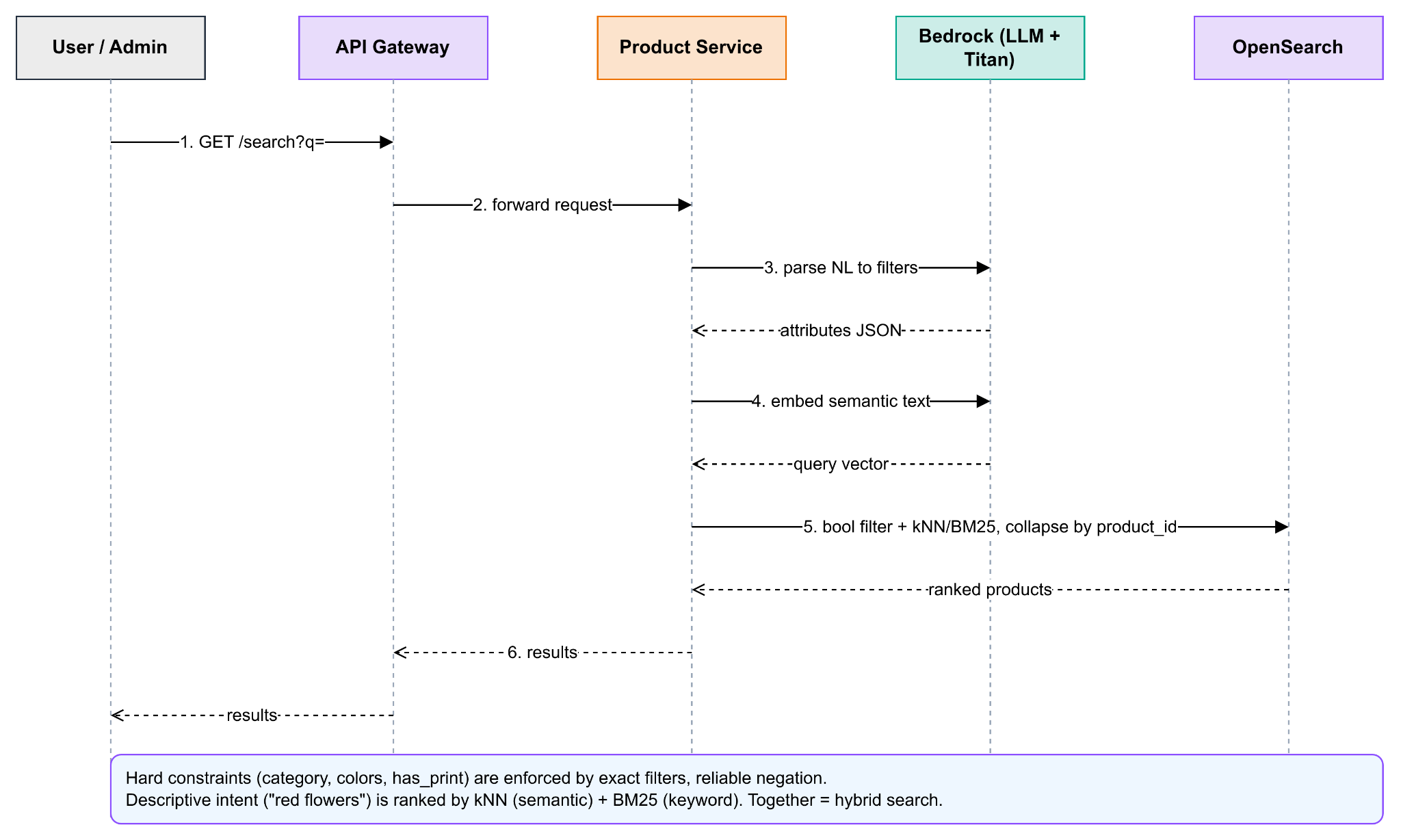
A natural-language query is parsed by a Bedrock LLM (prompted with the shared vocabulary) into structured filters plus a residual semantic query. The Product Service maps that JSON to a query—the model never touches the datastore directly.
Three search modes combine:
- 1. Keyword search: BM25 over the model-generated description for lexical matches.
- 2. Semantic search: kNN over the embedding; the query text is embedded with the same Titan model used at indexing time (vectors only compare within one model's space, so upgrading the embedding model means re-embedding all images).
- 3. Hybrid search: Hard constraints (category, colours,
has_print) are enforced as exact filters, giving reliable negation, while descriptive intent ("red flowers") is ranked by the combined semantic + keyword score. Results are collapsed byproduct_idto return one hit per product.
6. Data Model
Aurora PostgreSQL Schema (Source of Truth):

Tables at a Glance:
products: Catalogue entity, the merchant-facing product record and its CRUD surface.product_images: Raw image rows (one per image), stays stable and carries the idempotency hash.image_analysis: AI-derived metadata, 1:1 with an image and fully regenerable. The four fields the example queries filter on (category,colors,pattern,has_print) are first-class columns; the rest live inattributes(JSONB) and are covered bydescription+embeddingfor semantic search.
Searchable Attributes: The AI extracts structured attributes that support exact filtering alongside semantic search.
| Attribute | Purpose |
|---|---|
| Category | Product type (dress, t-shirt, shoes, etc.) |
| Colors | Exact colour filtering |
| Pattern | Floral, striped, plain, etc. |
| Has Print | Enables queries such as "green t-shirt with no prints" |
| Description | AI-generated text used for keyword (BM25) search |
| Embedding | Vector representation used for semantic similarity search |
| Attributes (JSON) | Additional metadata such as sleeve length, neckline, fit, or material that can evolve without schema changes |
OpenSearch Index Mapping (Search Engine): OpenSearch stores an optimized search document for every analysed image.
Each indexed document contains:
- Product identifier (
product_id) - Image identifier (
image_id) - Product information (name, brand)
- Searchable AI attributes
- AI-generated description
- Vector embedding
This enables three complementary search modes:
- Keyword Search (BM25) for lexical matching.
- Semantic Search (kNN) using vector embeddings.
- Hybrid Search combining exact filters (
category,colors,has_print) with semantic ranking to provide accurate and relevant results.
7. Design Decisions
| Decision | Reason |
|---|---|
| S3 | Durable, cheap object storage for the source images. |
| SQS (+ DLQ) | Decouples and rate-limits AI processing, isolates failures. |
| Worker Lambda | Elastic, pay-per-use background AI analysis. |
| Bedrock VLM | Zero-shot fine-grained attributes (incl. has_print) with no labelled training data. |
| Titan Multimodal Embeddings | Shared image/text vector space enables semantic recall from text queries. |
| Aurora Postgres + pgvector | Relational source of truth with clean CRUD, durable vectors for reindexing. |
| OpenSearch | Single engine for exact filters + BM25 + kNN (hybrid search). |
| API Gateway + Product Service | Node.js microservice (ECS/Fargate) on the read path, persistent OpenSearch pooling, microservice-stack fit. |
| Bedrock Batch Inference | Cheaper, throughput-friendly path for the one-time 100k backfill. |
| Controlled Vocabulary | Consistent enums (categories, colours, patterns) so filters never silently miss (e.g., red vs crimson). |
8. Scalability & Reliability
- Queue-based processing absorbs the 100k backfill and ongoing additions at a controlled rate.
- Horizontal worker scaling via Lambda concurrency, capped to respect Bedrock quotas.
- Automatic retries with exponential backoff for transient model/throttling errors.
- Dead-letter queue captures permanently failed jobs for inspection and replay.
- Idempotent processing (
s3_key+content_hash) makes retries and replays safe. - OpenSearch is rebuildable from Aurora at any time; no AI re-run required.
- Model versioning (
model_version) enables targeted reprocessing on model or taxonomy changes. - Batch Inference path keeps the one-time seed cheap and within throughput limits.
9. Trade-offs
| Choice | Alternative | Why |
|---|---|---|
| Aurora Postgres + pgvector | DynamoDB | Relational catalogue with joins and easy admin CRUD; DynamoDB only wins at millions with pure key-value access. |
| Hybrid (filters + vectors) | Pure vector search | Pure vectors fail negation and exact colour/category filtering. |
| Bedrock VLM | Rekognition / Custom Labels | Fine-grained attributes zero-shot, no labelled data or per-attribute training. |
| Asynchronous (SQS + worker) | Synchronous analysis | Decoupled, retryable, and resilient to spikes and model throttling. |
| OpenSearch | SQL LIKE | Real relevance, semantic recall, and scale. |
| Batch Inference for seed | 100k on-demand calls | ~50% cheaper and respects throughput quotas. |
| Product Service (ECS/Fargate) | Search Lambda | Persistent OpenSearch connection pooling and microservice stack fit; Lambda only preferable for scale-to-zero, spiky low volume. |
Note: For the current requirement of approximately 100,000 images, a solution based on PostgreSQL with full-text search (tsvector) and pgvector would be sufficient. This design adopts OpenSearch to provide a clear path for hybrid search, richer text relevance, faceted filtering, and future scalability as the product catalogue and search traffic grow.